Getting Started
Try It Out
Experience our computer vision API that combines YOLO-based element detection with advanced vision models to understand and interact with any interface. Simply describe what you want to do, and we'll identify the exact element and provide precise coordinates for interaction.
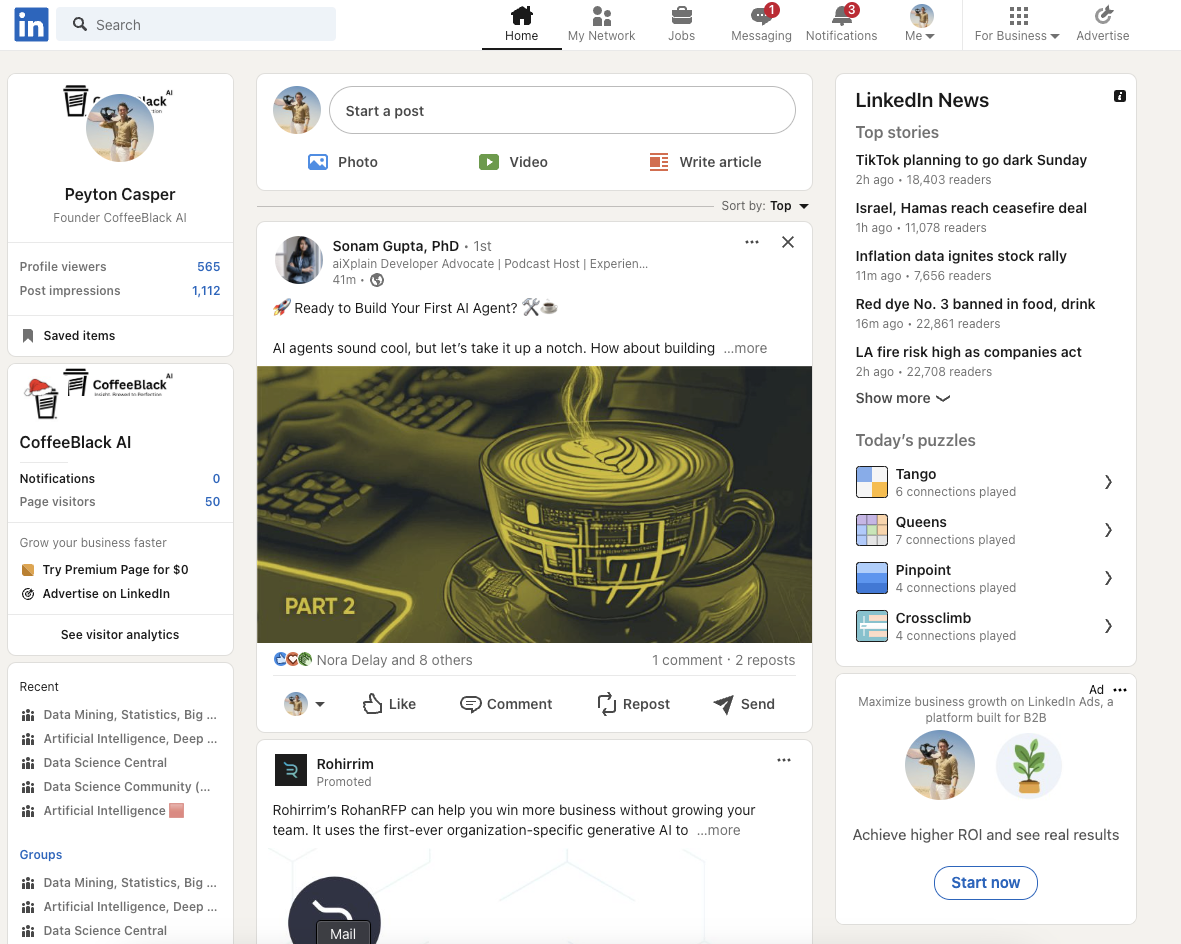
Step 1: Element Detection
Our YOLO model first identifies all interactive elements like inputs, buttons, and links in the interface.
> Search for 'Peyton Casper'
Step 2: Natural Language Understanding
The vision model analyzes each element's visual and contextual properties to understand its purpose and relationship to your request.
> Click on the Messaging button
Step 3: Precise Interaction
The API returns exact coordinates and interaction type (click, type, scroll) for the most relevant element.
> Click on the Start Now button in the bottom right corner